
Quick Take: DeepSeek just unleashed R1-0528, a monster upgrade to their reasoning model that’s now breathing down the necks of giants like OpenAI’s O3 and Google’s Gemini 2.5 Pro. The headline wins? AIME 2025 accuracy skyrocketed from 70% to a stunning 87.5%, coding performance got a massive boost, and they’ve finally added proper system prompt support. Even sweeter, they’ve distilled this reasoning prowess into an 8B model that punches way above its weight.
🚀 The Developer Crunch:
🎯 Why This Matters for Devs: DeepSeek’s R1-0528 isn’t just another model update; it’s a serious contender bringing top-tier reasoning to the open-source world, with performance nipping at the heels of closed-source giants. For you, this means access to significantly improved coding assistance, mathematical problem-solving, and complex workflow automation. Plus, the 8B distilled version makes this advanced reasoning genuinely accessible for local deployment and experimentation. Time to level up your AI-powered dev tools!
Key Actionable Features & Wins:
-
Proper System Prompt Support: Finally! No more clunky “
<think>\\n” prefixes. R1-0528 now handles system prompts like a pro, making integration smoother and more intuitive. - Massive Performance Leaps: Get ready for some serious brainpower. AIME 2025 accuracy jumped from 70% to a whopping 87.5%. LiveCodeBench coding scores climbed from 63.5% to 73.3%, and its Codeforces rating shot up from 1530 to 1930. These are game-changing improvements.
-
Pocket Rocket 8B Distilled Model: Need elite reasoning locally? The
DeepSeek-R1-0528-Qwen3-8Bdistilled model delivers an incredible 86% on AIME 2024, matching much larger models. Perfect for on-device or resource-constrained scenarios. - OpenAI-Compatible API: Drop it straight into your existing workflows. Access R1-0528 via platform.deepseek.com using the familiar OpenAI API interface.
- Enhanced Function Calling: Expect more reliable tool integration and significantly reduced hallucination rates, making it more robust for production-grade agentic workflows.
⚡ Developer Tip: This is your cue to test out advanced reasoning capabilities for those complex coding challenges, mathematical problem-solving tasks, or intricate multi-step workflows that previously stumped other models. The 8B distilled version is particularly exciting – grab it from Hugging Face and see how much reasoning power you can pack into local deployment scenarios. Don’t forget to enable “DeepThink” mode on chat.deepseek.com for a spin!
Critical Caveats & Considerations
- Token Usage & Cost: The enhanced reasoning comes at a cost – average token usage per task has nearly doubled (from ~12K to ~23K). Factor this into your API budget if using the hosted version.
- MIT License = Commercial Friendly: Good news! The MIT license means you can leverage this powerful model for your commercial applications without restrictive licensing headaches.
- “DeepThink” Mode: When using the chat interface, ensure “DeepThink” mode is enabled to access the new reasoning capabilities.
🌐 Availability: It’s live and kicking! Test it on chat.deepseek.com (remember to enable “DeepThink” mode!), integrate via the API at platform.deepseek.com, or grab the models for local deployment from GitHub and Hugging Face.
🔬 The Deeper Dive
Beyond Incremental Gains: So, what’s the real story behind DeepSeek-R1-0528? This isn’t just another routine model refresh. It represents a significant leap in how open-source reasoning models can tackle complex problems, and the benchmark numbers are telling a compelling story.
🔬 Technical Deep Dive: The Power of “Thinking Depth”
The core breakthrough with R1-0528 seems to be a deliberate strategy of investing more computational resources into each reasoning task. DeepSeek has nearly doubled the average token usage per task. While this means higher token consumption, the payoff is a dramatic improvement in reasoning quality, pushing the model into territory previously dominated by closed-source giants. This “thinking depth” allows the model to explore more complex reasoning chains and arrive at more accurate and nuanced solutions.
The benchmark improvements aren’t just marginal; they’re substantial across a range of challenging tasks. GPQA-Diamond saw a jump from 71.5% to an impressive 81%. For developers focused on competitive programming or complex algorithm generation, the Codeforces rating increase of 400 points (from 1530 to 1930) is a clear indicator of enhanced coding logic. Furthermore, SWE-Verified (Software Engineering Verification) scores climbed from 49.2% to 57.6%. These aren’t just numbers; they represent tangible improvements in capabilities that directly impact real-world production use cases.
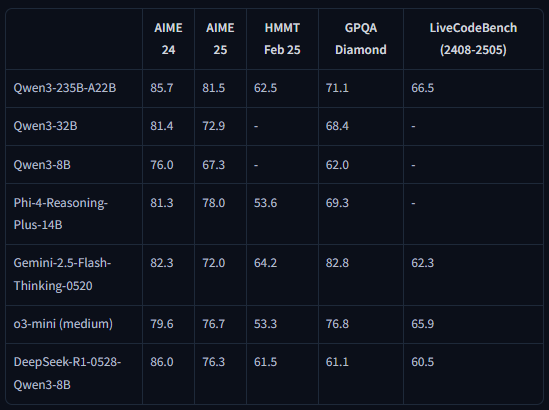
The 8B Distillate: Democratizing Elite Reasoning
Perhaps one of the most exciting aspects of this release is the 8B distilled model: DeepSeek-R1-0528-Qwen3-8B. DeepSeek ingeniously took the sophisticated reasoning chains generated by the full R1-0528 model and used them to post-train the Qwen3 8B Base model. The outcome is nothing short of remarkable: a compact 8B model that achieves an astounding 86% on AIME 2024. This effectively matches the performance of vastly larger models, like Qwen3-235B-thinking, while being readily deployable on consumer-grade hardware.
💡 This distillation technique is a potential game-changer for the AI industry. It demonstrates that elite reasoning capabilities aren’t solely the domain of massive, resource-hungry models. Transferring this power to smaller, more accessible models is huge for democratizing access to sophisticated AI and enabling innovative on-device applications.
From a practical implementation standpoint, DeepSeek has also smoothed out some of the previous version’s rough edges. The earlier requirement to manually prefix prompts with “<think>\\n” to activate reasoning mode was cumbersome, especially for production systems. R1-0528 now boasts proper system prompt support and handles the activation of its reasoning capabilities automatically. They’ve also provided detailed prompt templates to guide developers in leveraging features like file uploading and web search integration, further streamlining development.
The commercial implications of this release are also significant. With its permissive MIT license, companies can confidently build commercial applications on top of DeepSeek R1-0528 without the licensing restrictions that accompany some other high-performing models. Coupled with its OpenAI-compatible API, it’s strategically positioned as a compelling drop-in alternative for development teams looking to optimize costs, gain more control over their AI stack, or tap into open-source innovation.
🎯 TLDR: DeepSeek’s R1 just got a massive brain transplant! R1-0528 delivers elite reasoning, rivaling top-tier models like O3, while staying open source & commercially friendly. The distilled 8B version is a tiny titan, making advanced AI accessible to everyone. System prompts fixed, coding skills boosted – go build something smart!



